浅谈一种黑科技--索引树优化块状链表
众所周知,块状链表实现平衡树是 的,且不用一些手段卡不过加强版,那么有没有什么科技可以让块链达到 呢?
有的兄弟,有的。在 Python 的第三方库 Sorted Containers 里实现了一种块状链表,通过建索引树倍增优化查找过程,使得单次操作的复杂度降到了均摊 。
这种块链跑的飞快,在 mmap 快读加持下直接跑到平衡树加强版的次优解,C++ 的最优解。下面我们来讲解索引树优化块状链表的方法。其实这玩意就是单层跳表。
实现
阅读这里的 Python 代码需要一定的 Python 基础和 Pythonic 技巧。 如果您不会 Python,可以直接看 C++ 版实现。
首先你要下载 sortedcontainers 库,然后打开 sortedlist.py 阅读源码。
内部结构
先找到 SortedList 类,我们看看它的 __init__ 函数:
1 | |
参考这篇知乎回答,我们来看看这些变量都是什么:
_len:列表的长度;_load:类似于块长,当块长大于二倍时分裂,小于一半时合并。sortedcontainers里的默认块长DEFAULT_LOAD_FACTOR是 ,本蒟蒻实测 C++ 取 效率较好。_lists:就是块状链表,由于list的插入删除常数很小,直接用list套list实现,它里面的每个列表都要有序。_maxes:块内最大值。这样我们可以二分找到元素所属块。_index:索引树,我们稍后讲解。_offset:偏移量,与索引树的层数有关。
分析完这些后,我们可以写出 C++ 版的代码:
1 | |
索引树
索引树的构建方法是,以这些块的长度为叶子节点,自顶向上两两合并。例如对于 [[1, 2, 3], [4, 5], [6, 7, 8, 9], [10, 11, 12, 13, 14]],我们建立的索引树如图:
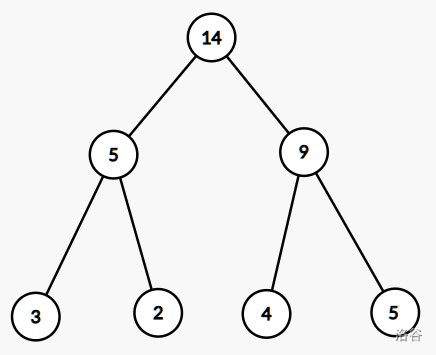
这是个 Leafy Tree。因为这玩意是个满二叉树,可以堆式存储,而 _offset 维护的就是叶子节点的开始下标,在这里就是 。
我们写出 C++ 版本的建树代码:
1 | |
Python 版本建树
1 | |
首先建叶子层使用了 map 函数,它类似于 C++ 中的 std::for_each,对于每个范围内的元素作 len 操作,这样就得到了叶子节点。接下来这几行代码:
1 | |
zip 的作用是把 head 和 tail 压到一起,由于这里 head 和 tail 指向同一个迭代器,因此 zip(head, tail) 是两两交替的。starmap 函数是 map 的二元版本,通过这种操作,我们就得到了倒数第二层。之后建树同理。
1 | |
通过一行代码就实现了将 tree 中的元素翻转后,不断加到 _index 上。
位置操作
这里的位置操作有两种,分别是 loc 和 pos。loc 操作是将形如第几个块的第几个元素转换为整个列表的第几个元素,pos 则相反。我们先来看 pos 操作:
1 | |
不用看那堆异常处理,直接看循环部分。当 idx 小于左子树大小时进左子树找,否则减去左子树大小并进右子树找,这和 BST 的查询操作是一致的。我们来分析一下复杂度,不妨设我们分了 块,那么满二叉树上的一条根链为 级别。当 时,查询复杂度为 。再来看看 _loc 函数:
1 | |
就是借助索引树来倍增跳。复杂度分析与上面相同,为 。写出 C++ 代码:
1 | |
插入
找到 add 函数:
1 | |
- 首先当块链为空时,直接在末尾加入即可。
- 否则我们二分找到
val所属块。这里bisect_right的行为类似于std::upper_bound,返回下标。 -
- 若
val无后继,说明它直接放到最后一个块的末尾即可,同时更新块内最值。 - 否则,在块内插入
val,并且维护块链性质。
- 若
写出 C++ 版代码:
1 | |
expand 操作
1 | |
这个函数有两条逻辑。首先当块长大于二倍 load 时,执行分裂操作,把这块从中间分成两块,然后清空索引树(这里一定要清空,本蒟蒻被这个卡了 4h)。不分裂且建好索引树时,我们把这个块到根节点链上的值都加一。C++ 版如下:
1 | |
删除
找到 discard 函数:
1 | |
在二分找到 value 后调用了 _delete 函数,找到它:
1 | |
一个大分讨的结构:
- 若块长大于一半的
load,更新块内的最大值,然后把在索引树上把该块到根节点的路径值减一; - 否则,若块数大于 ,将该块合并到上一块,若当前块为第一块就合并到下一块。由于这样完了也会导致块长大于二倍
load,执行expand操作; - 否则,若删除此元素后列表不为空,直接维护块内最大值;
- 否则,清空列表。
C++ 实现:
1 | |
查询第 小
kth 操作在 Python 里是重载的 [] 运算符,找到 __getitem__ 函数:
1 | |
前面那一大坨是 Python 的切片索引,不用管它。就是用 pos 函数找到哪个块和块内索引直接返回即可。C++ 实现:
1 | |
查询排名
Python 里有两种排名:bisect_left 和 bisect_right,对应 C++ 中的 std::lower_bound 与 std::upper_bound。我们找到这两个东西:
1 | |
用对应的二分函数找到哪个块和它在块内的位置,用 loc 函数转换。C++ 实现:
1 | |
基于这个东西,我们可以用 upper_bound(x) - lower_bound(x) 来实现计数功能。加点剪枝:
1 | |
这样我们就实现了一个功能比较完整的有序列表了。
复杂度分析
首先设我们分成了 块。
在修改时,分裂合并由均摊分析可得,总复杂度不超过 。而更新索引树是 的。瓶颈在插入删除为 。但是众所周知 std::vector 的插入删除常数很小,在 数据下约是 级别,因此我们可以认为 跑的比 还快,这样复杂度就是 了。Sorted Containers 文档里也是这么写的:
1 | |
对于查询操作,二分显然是 的,而 pos 和 loc 都在 层的索引树上操作,复杂度也是 。由均摊分析,建立索引树的次数不超过 次。
因此,你可以认为索引树优化块状链表的整体复杂度为 。
不知道这个东西能不能可持久化。
模板
这是一份完整的 sorted_vector 模板:
1 | |
如果要自定义比较顺序,需要重载运算符。
应用
理论上这种优化方法适用于所有块状链表。所以这里放几个块链题: